Chapter 0. Introduction
0. Learning objectives
Upon completion of this chapter, the student will understand
- The motivation of enhanced sampling methods.
- Key terminologies such as phase/configuration space, ensemble, Boltzmann distribution, collective variable, free energy profile, and potential of mean force.
- The derivation of the Boltzmann distribution, potential of mean force, and free energy profile.
1. Motivation of enhanced sampling methods
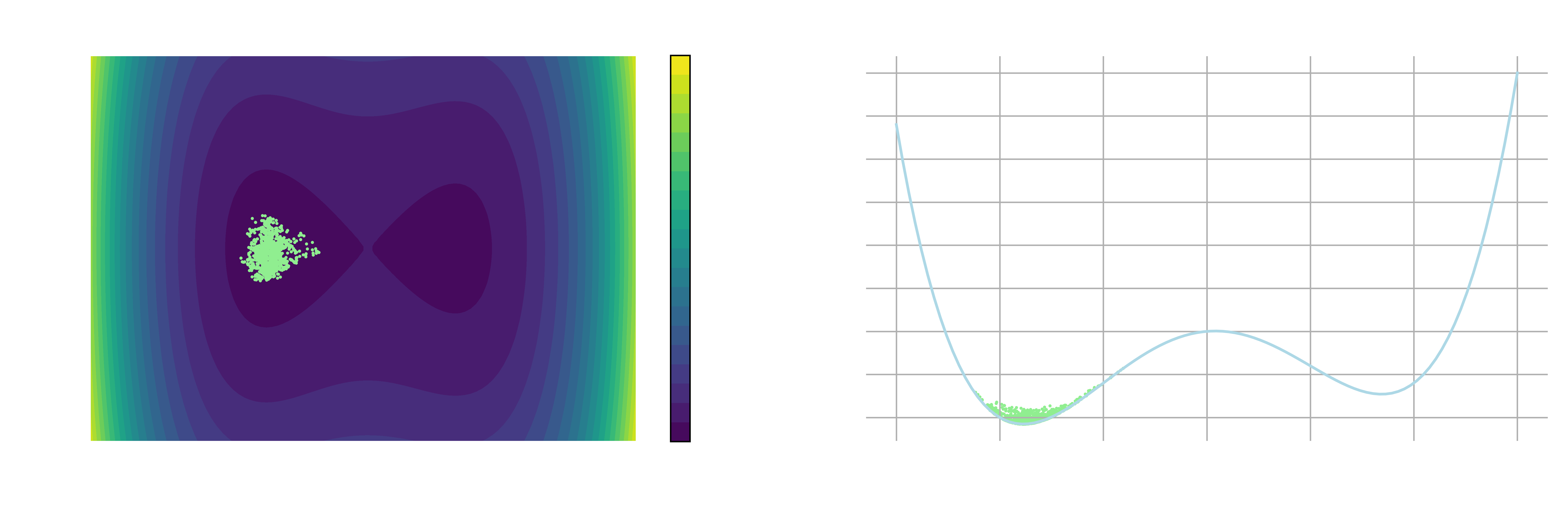
As supercomputing resources have become increasingly available in recent years1, molecular dynamics (MD) has become a standard tool for studying atomistic-level behaviors of molecular systems in various scientific disciplines2. However, an MD simulation can accurately describe the thermodynamic and structural properties of a system only if it achieves ergodicity during its simulation timescale. This means that the simulation must explore the phase space comprehensively, or equivalently, ensure that all possible configurations are sampled. This is usually a challenging task in real-world systems, as the metastable states of interest are frequently separated by substantial free energy barriers that are difficult to overcome by random fluctuations within a reasonable amount of time (see Figure 1 below, or the leftmost panel of Figure 1 in Chapter 2).
To overcome this limitation, researchers have developed various enhanced sampling methods in recent decades. One subset of these methods involves sampling along a set of predefined collective variables (CVs). These CVs, as we denote as a $d$-dimensional vector ${\bf \xi}=(\xi_{1}({\bf x}), \xi_2({\bf x}), …, \xi_d({\bf x}))$, can be any functions of the system coordinates ($\bf x$), such as torsions, coordination numbers, or radii of gyration. Ideally, CVs should represent a small number of degrees of freedom that capture the slowest degrees of freedom of the system and distinguish metastable states of interest. Some examples of CV-based methods include metadynamics, adaptive biasing force, umbrella sampling, and replica-exchange umbrella sampling, which will all be covered in this mini-course.
2. Terminologies
Before diving into the following chapters, we will review some key concepts in statistical mechanics by introducing a few terminologies one may come across in enhanced sampling methods. This section serves as a quick review of the essential concepts to better understand the tutorials in later chapters. Readers are encouraged to visit Section 2.2 (Glossary of essential notions) in the review by Hénin et al.3 for a more exhaustive list of terms.
Timescale
The real timescale of a molecular system can vary significantly depending on the size and complexity of the system, as well as the process of interest. As illustrated in Figure 2, the timescales of molecular motions can range from femtoseconds to seconds or even longer. For instance, bond vibrations, the fastest motion in a molecular system, typically occur on the order of femtoseconds. In contrast, biological processes such as allosteric transitions or protein-ligand binding have timescales considerably longer than bond vibrations, making the transitions between metastable states of interest rare events. This long timescale is due to the high free energy barriers separating metastable states, as discussed in the previous section.
Importantly, to ensure that the motion of atoms in a system is captured and no short-lived events are missed, such as bond vibrations and molecular rotations, the time step used in molecular dynamics simulations must be smaller than the shortest timescale in the system. This inevitably small time step makes simulations that study biological processes computationally expensive, easily requiring $10^8$ steps or more. To reduce the computational cost of simulating long-timescale processes, researchers frequently use enhanced sampling methods to bias the system towards the metastable states of interest. These methods make rare events more probable in a shorter timescale, thus reducing the number of required simulation steps.
Phase space and configuration space
In statistical mechanics, the phase space of a system is a space where all the possible states of the system can be represented. In three-dimensional Cartesian coordinate systems, a state is characterized by the coordinates ${\bf x} \in \mathbb{R}^{3N}$ and momenta ${\bf p} \in \mathbb{R}^{3N}$ of the system, where $N$ is the number of particles of the system. Consequently, each state can be represented by a unique point in the phase space, which is the joint space $({\bf x}, {\bf p})$.
In contrast, the configuration space is defined by all the possible configurations (defined solely by ${\bf x}$) of the system, so its dimensionality ($3N$) is half of that of the phase space ($6N$). When simulating long-timescale events using molecular dynamics, it is crucial to have sufficient sampling in the configuration space to capture the distribution of all possible configurations of the system. This ensures that rare events and transitions between different configurations are adequately represented. It is this need for comprehensive sampling in the configuration space motivates the development of enhanced sampling methods, which are the focus of this mini-course.
Microstate and macrostate
In the case where a system is composed of a larger number of particles, such as atoms or molecules, a microstate is a particular spatial arrangement of the particles in the system, i.e., a configuration. On the other hand, a macrostate, which can be defined by macroscopic thermodynamics variables (e.g., temperature, pressure, or total energy), is a collection of many possible microstates. For example, in a system composed of particles A and B that can either have an energy of 0 or 1, there are only three possible macrostates, which correspond to total energies of 0, 1, and 2, respectively. In the macrostate having a total energy of 2, there are two possible microstates: particles A and B having energies of 0 and 1, and the other way around.
Boltzmann distribution
To accurately calculate thermodynamic properties from molecular dynamics, we need to sample the Boltzmann distribution so that the system is at equilibrium. The Boltzmann distribution, sometimes called a Gibbs distribution, is a probability distribution that characterizes the distribution of states of a system in thermal equilibrium at a given temperature. It describes the probability of finding a particle in a particular energy state given its energy and the temperature of the system. Specifically, in the case where the energy levels are discrete, the normalized probability $p_i$ of finding the system being in state $i$ can be expressed as follows: $$\boxed{p_i = \frac{e^{-\beta E_i}}{\sum_i e^{-\beta E_i}} \propto e^{-\beta E_i}} \label{boltzmann_discrete} \tag{1}$$ where $E_i$ is the total energy (the sum of potential and kinetic energy) of state $i$, and $\beta = 1/k_{B}T$ is the inverse temperature (where $k_B$ is the Boltzmann constant ($1.38 \times 10^{-23} \text{ } \mathrm{J\cdot K^{-1}}$), and $T$ is the system temperature). Frequently, we denote the normalization constant as $Q=\sum_{i} e^{-\beta E_i}$, which is the so-called partition function.
In a phase space, where a state is defined by its continuous variables, coordinates ${\bf x}$ and momenta ${\bf p}$, we can rewrite the Boltzmann distribution as $$\boxed{\mu({\bf x}, {\bf p})=\frac{e^{-\beta(U({\bf x}) + K({\bf p}))}}{\int \int e^{-\beta(U({\bf x}) + K(\bf p))} d{\bf x}d{\bf p}} \propto e^{-\beta (U({\bf x}) + K({\bf p}))}} \label{boltzmann} \tag{2} $$ where $\mu({\bf x}, {\bf p})$, analogous to $p_i$ in the discrete space, is the probability of finding the system to have coordinates ${\bf x}$ and momenta ${\bf p}$. In this case, we have the partition function of the phase space $Q = \int \int e^{-\beta(U({\bf x}) + K(\bf p))} d{\bf x}d{\bf p}=\left ( \int e^{-\beta U({\bf x})}d{\bf x} \right ) \left (\int e^{-\beta K({\bf p})}d{\bf p} \right )$. Note that in Equation \ref{boltzmann}, we express the total energy as the sum of the potential energy $U({\bf x})$ and the kinetic energy $K({\bf p})$.
From Equation \ref{boltzmann}, we can derive the configurational distribution (the Boltzmann distribution in the configuration space) by integrating $\mu({\bf x}, {\bf p})$ with respect to the momenta ${\bf p}$: $$\nu({\bf x})=\int \mu({\bf x}, {\bf p}) d{\bf p}=\frac{1}{Q}\int e^{-\beta(U({\bf x})+K({\bf p}))}d {\bf p} = \frac{e^{-\beta U({\bf x})} \left ( \int e^{-\beta K({\bf p})}d{\bf p}\right )}{\left ( \int e^{-\beta U({\bf x})}d{\bf x} \right ) \left (\int e^{-\beta K({\bf p})}d{\bf p} \right )} \tag{3}$$ Finally, we have $$\boxed{\nu({\bf x})=\frac{e^{-\beta U({\bf x})}}{\int e^{-\beta U({\bf x})}d {\bf x}}\propto e^{-\beta U({\bf x})} \label{config_boltzmann}} \tag{4}$$ Frequently, Equation \ref{config_boltzmann} is written as $\nu({\bf x}) = \frac{1}{Z}e^{-\beta U({\bf x})}$, where $Z=\int e^{-\beta U({\bf x})}d{\bf x}$ is the configurational partition function.
Supplementary note: Maxwell-Boltzmann distribution
Different from the Boltzmann distribution, the Maxwell-Boltzmann distribution is a special case of the Boltzmann distribution. It is a probability distribution that describes the speed ($v$) of non-interacting gas particles in thermal equilibrium at a given temperature. In a three-dimensional velocity space, the Maxwell-Boltzmann distribution is given by $$f(v) = \left( \frac{m}{2\pi k_B T} \right)^{3/2} e^{-\frac{mv^2}{2k_B T}} \propto e^{-\frac{mv^2}{2k_B T}} \tag{S1}$$
Supplementary note: Derivation of the Boltzmann distribution
The derivation of the Boltzmann distribution (Equation \ref{boltzmann}) is based on the second law of thermodynamics, which states that any spontaneous process will tend to maximize the total entropy of the system. By definition, the entropy of a system can be expressed as $$S=k_{B}\ln W \tag{S2}$$ where $W$ is the multiplicity, i.e., the number of microstates corresponding to a particular macrostate of a thermodynamic system. Now, we consider a system of $N$ particles, where $n_i$ particles have an energy of $E_i$, i.e., $\sum_i n_i = N$. Then, the multiplicity $W$ can be expressed as $W=\frac{N!}{n_1!\cdot n_2! \cdot n_3!\cdot…}$. Hence, $$\ln W = \ln N! -\sum_{i}\ln n_i! \tag{S3}$$ By Stirling’s approximation ($\ln n! = n\ln n - n$), we have $$\ln W = \left (N \ln N - \bcancel{N} \right ) - \left (\sum_{i} n_i \ln n_i - \cancel{\sum_i n_i} \right )=N\ln N -\sum_i n_i \ln n_i \tag{S4}$$ Let the probability of finding a particle having an energy $E_i$ be $p_i=n_i/N$, we then have $$\ln W = N\ln N -\sum_i (Np_i) \ln (Np_i)=N \ln N - N\sum_i p_i (\ln N + \ln p_i)$$ $$= N \ln N - N \ln N \sum_i p_i - N \sum_i p_i \ln p_i =-N\sum_i p_i \ln p_i \tag{S5}$$ Given the entropy $S=k_B \ln W$, we have $$S/{k_B N} = -\sum_i p_i \ln p_i \tag{S6}$$ Now, the goal is to find $p_i$ that maximizes the entropy term $S/k_B N$ under the following two constraints:
- The sum of the probabilities should be 1, i.e., $\sum_i p_i = 1$
- The average energy of the particles should be $\bar{E}$, i.e., $\sum_i p_i E_i = \bar{E}$
To solve for $p_i$ that maximize $f$, we consider the following function: $$f(p_i) = -\sum_i p_i \ln p_i -\alpha \left (\sum_i p_i \right ) - \beta \left ( \sum_i p_i E_i\right ) \tag {S7}$$ where $\alpha$, $\beta$ are Language multipliers. (Note that $E_i$’s are a bunch of constants, not variables as $p_i$.) Then, we equate the partial derivatives of $f$ with respect to $p_i$ to 0, namely, $$\frac{\partial f}{\partial p_i}=0 \Rightarrow -\sum_i \ln p_i -\sum_i p_i \cdot \frac{1}{p_i}-\alpha - \beta \left (\sum_i E_i \right ) = 0 $$ $$\Rightarrow \sum_i \left ( -\ln p_i -1 -\alpha -\beta E_i\right )=0 \Rightarrow \boxed{p_i = e^{-(\alpha + 1)}e^{-\beta E_i} \propto e^{-\beta E_i}} \tag{S8} \label{partial_p}$$ Applying the normalization constraint $\sum_i p_i =1$, we have $$e^{-(\alpha + 1)}\sum_i e^{-\beta E_i}=1 \Rightarrow e^{-(\alpha + 1)} = \frac{1}{e^{-\beta E_i}} \tag{S9}$$ which means that $e^{-(\alpha + 1)}$ is the normalization constant. To get the expression of $\beta$, we consider the Maxwell relation $ \left(\frac{\partial S}{\partial U}\right )_{V, N}=\frac{1}{T}$.
Specifically, we have $$dU = d(N\bar{E}) = N d\left ( \sum_i p_i E_i\right )=N\sum_i E_i dp_i \tag{S10}$$ $$dS = -k_B N d\left ( \sum_i p_i \ln p_i\right)=-k_B N \sum_i (\ln p_i + 1) dp_i$$ $$ \Rightarrow dS=-k_B N \sum_i (-\alpha -\beta E_i)dp_i \tag{S11}$$ Given that $\sum_i p_i=1\Rightarrow \sum_i dp_i=0$, $dS$ can be simplied as follows: $$dS = \alpha k_B N\cancelto{0}{\sum_i dp_i}+ \beta k_B \left(N\sum_i E_i dp_i\right)=\beta k_B dU \tag{S12}$$ Hence, $$\left(\frac{\partial S}{\partial U}\right )_{V, N}=\beta k_B=\frac{1}{T}\Rightarrow \boxed{\beta = \frac{1}{k_B T}} \tag{S13} \label{beta}$$ Altogether, Equations \ref{partial_p} and \ref{beta} derive the expression of the Boltzmann distribution, i.e., Equation \ref{boltzmann_discrete}.
Ensemble
In statistical mechanics, an ensemble is a collection of hypothetical copies of a system that all share the same macroscopic properties (such as temperature, pressure, volume, and chemical potential) but may differ in their microscopic details (such as the positions and velocities of individual particles). Some of the most common thermodynamic ensembles include
- NVT ensemble: The NVT ensemble is also called the canonical ensemble, where the number of particles ($N$), volume ($V$), and temperature ($T$) are fixed. The probability distribution and the corresponding partition function for the NVT ensemble are given by the Boltzmann distribution, namely, $$p_i = \frac{e^{-\beta E_i}}{\sum_i e^{-\beta E_i}}, \text{ } Z_{NVT} = \sum_i e^{-\beta E_i} \tag{5}$$
- NPT ensemble: The NPT ensemble is also called the isothermal-isobaric ensemble, or the Gibbs ensemble, where the number of particles ($N$), pressure($P$), and temperature ($T$) are fixed. The probability distribution and partition function of the NPT ensemble is given below: $$p_i = \frac{e^{-\beta E_i}e^{-\beta PV_i}}{\sum_i e^{-\beta E_i}e^{-\beta PV_i}}, \text{ } Z_{NPT} = \sum_i e^{-\beta E_i}e^{-\beta PV_i} \tag{6}$$
- NVE ensemble: The NVE ensemble is also called the microcanonical ensemble. The NVE ensemble is defined by assigning an equal probability to every microstate whose energy falls within a range centered at $E$, and all the other microstates are given a probability of 0. That is, the probability in the NVE ensemble can be written as $p_i = 1/W$, where $W$ is the number of microstates within the range of energy.
- $\mu$VT ensemble: The $\mu$VT ensemble is also called the grand canonical ensemble, where the chemical potential ($\mu$), volume ($V$) and temperature ($T$) are fixed. The probability distribution and partition function of the $\mu VT$ ensemble is given below: $$p_i = \frac{e^{-\beta E_i}e^{\beta \mu N_i}}{\sum_i e^{-\beta E_i}e^{\beta \mu N_i}}, \text{ } Z_{\mu VT} = \sum_i e^{-\beta E_i}e^{\beta \mu N_i} \tag{7}$$
Notably, given the copies of the system in an ensemble, we can calculate the ensemble average of an observable $O({\bf x}, {\bf p})$ of interest, which is simply taking the average of $O({\bf x}, {\bf p})$ considering all points $({\bf x}, {\bf p})$ in the phase space: $$\langle O \rangle = \int O({\bf x}, {\bf p})\mu({\bf x}, {\bf p})d{\bf x}d{\bf p} \tag{8}$$
Ergodicity
The dynamics of a system is said to be ergodic if the ensemble average of the observable $O({\bf x}, {\bf p})$ of interest is equal to the time average of the observable over an infinitely long trajectory, namely, $$\langle O \rangle = \int O({\bf x}, {\bf p})\mu({\bf x}, {\bf p})d{\bf x}d{\bf p} = \lim_{M\rightarrow \infty} \sum_{t=1}^M O({\bf x}_t, {\bf p}_t) \tag{9}$$ In simple terms, if one monitors an obervable of interest for a single particle over a sufficiently long period of time and take the average of the observable at all time frames, the outcome would be equivalent to the average of the same observable computed over all possible configurations of the system at a single instant. In practice, given that it is impractical to identify all possible configurations at any given time frame, reaching ergodicity in molecular dynamics is essential as it allows one to estimate the ensemble average by computing the time average over a sufficiently long trajectory.
Metastable state
Metastable states are the states having a higher potential energy than the ground state but are stable enough for the system to reside for an extended (but finite) amount of time. For example, there are two metastable states in Figure 1. One has values of $x_2$ around -1.8, while the other has values of $x_2$ around 1.8.
Collective variable (CV)
Here, we refer to collective variables (CVs) as a $d$-dimensional vector ${\bf \xi}=(\xi_{1}({\bf x}), \xi_2({\bf x}), …, \xi_d({\bf x}))$, which can be seen as a lower-dimensional representation reduced/projected from the full $3N$-dimensional configurations ${\bf x}$ via the mapping function $\Phi({\bf x})={\bf \xi}$, with $d \ll 3N$. Traditionally, CVs can be defined as any functions of the coordinates of the system, but could additionally include the alchemical variable, as shown in a recent paper proposing alchemical metadynamics4, the method we will explore in Chapter 7.
Ideally, an optimal set of CVs should be able to capture the slowest dynamics of the system and distinguish the metastable states of interest. For example, in Figure 1, $x_1$ is a reliable CV for distinguishing the two metastable states of interest. Conversely, $x_2$ is orthogonal to the slowest degree of freedom of the system and, therefore, is not suitable for describing transitions between the two metastable states. Identifying the optimal set of CVs is often challenging in systems where the slowest-relaxing coordinates are not intuitive. In such cases, machine learning-based algorithms like RAVE5 or SGOOP6 can be helpful.
Free energy
In the canonical (NVT) ensemble, Helmholtz free energy is defined as $$F=-\frac{1}{\beta}\ln Z_{NVT}=-\frac{1}{\beta}\int e^{-\beta U({\bf x})}d{\bf x}\tag{10}$$ while in the Gibbs (NPT) ensemble, the Gibbs free energy can be expessed as $$G=F+PV=-\frac{1}{\beta}\left[ \ln Z_{NVT} - \left( \frac{\partial \ln Z_{NVT}}{\partial \ln V} \right )\right] \tag{11}$$ Practically, in a soluted system where the solvent is nearly imcompressible, i.e., $\frac{\partial V}{\partial P}\approx 0$, the difference in Gibbs free energy is almost equal to the difference in Helmholtz free energy.
Free energy profile
A free energy profile is meaningful only if there is a collective variable ${\bf \xi}$ of interest. A free energy profile, sometimes called a free energy landscape or a free energy surface, can be computed as follows: $$\boxed{F({\bf \xi})=-\frac{1}{\beta}\ln P({\bf \xi}) = -\frac{1}{\beta}\ln \int \delta({\bf \xi} - \Phi({\bf x}))\nu({\bf x})d{\bf x}=-\frac{1}{\beta}\langle \delta({\bf \xi}-{\bf \xi}({\bf x}))\rangle} \label{free_energy}\tag{12}$$ where $\nu({\bf x})=e^{-\beta U({\bf x})}/\int e^{-\beta U({\bf x})} d{\bf x}$ is the Boltzmann distribution and $\Phi$ is a function mapping the $3N$-dimensional vector ${\bf x}$ to the $d$-dimensional CV vector ${\bf \xi}$. The function $\delta$ is the multivariate Dirac delta function, i.e., $$\delta({\bf \xi}-\Phi({\bf x}))=\prod_i^d \delta'(\xi_i-\Phi_i({\bf x})), \text{ } \delta'(\xi_i-\Phi_i({\bf x}))=\begin{cases}+\infty \text{, if } \xi_i=\Phi_i({\bf x})\\ 0 \text{, otherwise} \end{cases}\tag{13}\label{delta}$$ where $\delta’$ is a single-variable Dirac delta function and $\Phi_i$ is a function mapping ${\bf x}$ to the $i$-th CV, $\xi_i$. While Equations \ref{free_energy} and \ref{delta} may seem daunting, they essentially mean that the free energy profile along the CVs can be computed from the marginal probability density $P({\bf x})$ along the CVs, which is obtained by integrating the Boltzmann distribution $\nu({\bf x})$ over all variables except for the CVs $\Phi({\bf x})$. This interpretation may be understood more easily with the example in the Supplementary note below.
In this example, given the potential energy $U(x_1, x_2)=x_1^4-6x_1^2 + x_1 + x_2^2$ (the same functional form as the one in the free energy surface in Figure 1), we want to determine its free energy profile along the collective variable $x_1$. First, we can calculate the Boltzmann distribution $$\nu(x)=\frac{1}{Z}\exp\left(-\beta(x_1^4-6x_1^2+x_1)\right)\exp(-\beta x_2^2)\tag{S14}$$ where $Z=\int \int \exp\left (-\beta(x_1^4-6x_1^2+x_1)\right)\exp(-\beta x_2^2) dx_1 dx_2$ is a spearable integral. To save space, we let $f(x_1)=x_1^4-6x_1^2+x_1$, so $\nu(x)=\frac{1}{Z}e^{-\beta f(x_1)}e^{-\beta x_2^2}$ and $Z=(\int e^{-\beta f(x_1)}dx_1)(\int e^{-\beta x_2^2} dx_2)$. Then, given that $x_1$ is the only CV, we can compute the free energy profile $F(x_1)$ as follows: $$F(x_1)=-\frac{1}{\beta}\ln \left (\int \int \delta’(x_1-\Phi_1({\bf x}))\nu(x_1, x_2)dx_1dx_2\right )$$ $$=-\frac{1}{\beta}\ln \left [ \left (\int_{-\infty}^{+\infty} \delta’\left (x_1-\Phi_1({\bf x})\right)e^{-\beta f(x_1)}dx_1\right)\left ( \int_{-\infty}^{+\infty} e^{-\beta x_2^2}dx_2\right)\right]\label{f_x_1} \tag{S15}$$ where $\Phi_1({\bf x})$ takes in ${\bf x}$ (and maps it to a specific value of $x_1$), but is a function of $x_1$ and therefore, can be grouped into the first integral in Eequation \ref{f_x_1}. Importantly, the value $x_1$ runs from $-\infty$ to $+\infty$ and whenever it is not equal to $\Phi_1({\bf x})$, the detal function $\delta’(x_1-\Phi_1({\bf x}))$ returns 0. In fact, given $\int f(x)\delta’(x-y)dx=f(y)$ (and $\left ( \int_{-\infty}^{+\infty} e^{-\beta x_2^2}dx_2\right)=\sqrt{\pi/\beta}$), we have $$F(x_1) = -\frac{1}{\beta}\ln \left(e^{-\beta f(x_1)} \cdot \sqrt{\frac{\pi}{\beta}} \right )\Rightarrow \boxed{F(x_1)=x_1^4 -6x_1^2+x_1-\frac{1}{\beta}\ln (\sqrt\frac{\pi}{\beta})} \tag{S16}$$ The same result can be reached by integrating the Boltzmann distribution overall all variables but not $x_1$, i.e., $$F(x_1) = -\frac{1}{\beta}\ln \left( \int e^{-\beta U(x_1, x_2)}dx_2 \right ) = x_1^4 -6x_1^2+x_1-\frac{1}{\beta}\ln (\sqrt\frac{\pi}{\beta}) \tag{S17}$$Supplementary note: An example of analytical free energy profile
Free energy estimator
A free energy estimator is an expression or algorithm that is used to estimate free energy differences or free energy surfaces from simulation data, such as configurations, energies, and forces. Other than estimating free energy by directly measuring the probability ratios or from transition matrices, common free energy estimators include weighted histogram analysis method (WHAM)7, thermodynamic integration (TI)8, Bennett acceptance ratio (BAR)9, and multistate Bennett acceptance ratio (MBAR)10. These free energy estimators will be briefly introduced in the following chapters.
Potential of mean force (PMF)
While the term potential of mean force (PMF) is frequently used interchangeably with free energy surface, the historical definition of PMF is defined between two particles 1 and 2 and represents the effective potential energy that particle 1 experiences due to the presence of particle 2, when the positions of all other particles in the system are averaged over. It is defined based on the radial distribution function $g(r)$: $$\boxed{W(r)=-\frac{1}{\beta}\ln g(r) = F(r) + \frac{2}{\beta} \ln r + C} \tag{14}$$ where $F(r)$ is the free energy surface along the interparticle distance and $C$ is an arbitrary constant. That is, the historic definition of PMF is related to the free energy surface but is still a distinct quantity. Check the Supplementary note below to see how PMF relates to the radial distribution function. In this mini-course, we treat the term “potential of mean force” equivalently as the term “free energy profile”.
$$P^{(n)}({\bf r}_1, ..., {\bf r}_n) = \int ... \int \frac{e^{-\beta U_N}}{Z_N} d{\bf r}_{n+1} ... d{\bf r}_N \tag{S20}$$
Assuming that the particles are indistinguishable, here we define the n-particle density function: $$\rho^{(n)}(d{\bf r}_1...d{\bf r}_N)=\frac{N!}{(N-n)!}P^{(N)}({\bf r}_1, ..., {\bf r}_n) $$ $$\Rightarrow \rho^{(n)}(d{\bf r}_1...d{\bf r}_N) = \frac{N!}{(N-n)!}\int ... \int \frac{e^{-\beta U_N}}{Z_N} d{\bf r}_{n+1} ... d{\bf r}_N \tag{S21}$$ which represents the probability density of finding any particle at ${\bf r}_1$, any particle at ${\bf r}_2$, ..., and any particle at ${\bf r}_n$. (Note that for $n=1$ (one-particle density), we have $\rho^{(1)}({ \bf r})=\rho$, the bulk number density. See Wikipedia or LibreTexts for the proof.)2. General correlation functionsA general correlation function can be defined in terms of the distribution function $\rho^{(n)}({\bf r}_1, ..., {\bf r}_n)$ as $$g^{(n)}({\bf r}_1, ..., {\bf r}_n)=\rho^{(n)}({\bf r}_1, ..., {\bf r}_n) / \rho^n $$ $$ \Rightarrow g^{(n)}({\bf r}_1, ..., {\bf r}_n) = \left ( \frac{V}{N}\right )^n \frac{N!}{(N-n)!}\int ... \int \frac{e^{-\beta U_N}}{Z_N} d{\bf r}_{n+1} ... d{\bf r}_N \tag{S22}$$ Specifically, for $n=2$, we have the so-called pair correlation functions. Note that $g^{(2)}({\bf r}_1, {\bf r}_2)$ can be rewritten as $g(r)=g(|{\bf r}_1-{\bf r}_2|)$, so that a pair of particles (with one of them being at the origin) separated by a distance $r$ is considered. $$g^{(2)}({\bf r}_1, {\bf r}_2)=\boxed{g(r)=\frac{1}{\rho^2} N(N-1)\int ... \int \frac{e^{-\beta U_N}}{Z_N} d{\bf r}_{3} ... d{\bf r}_N} \label{RDF}\tag{S23}$$ 3. Potential of mean force (PMF)Finally, here we relate the pair correlation function/radial distribution function $g(r)$ to the mean force $\langle F \rangle$, which is the negative derivative of the potential of mean force (PMF) $W$. Here, we consider the mean force that particle 1 experiences due to the presence of particle 2: $$\langle F_1 \rangle = -\langle \frac{d}{d{\bf r}_1} U_N({\bf r}_1, ..., {\bf r}_N)\rangle_{{\bf r}_1, {\bf r}_2} = \frac{- \int ... \int \left ( \frac{dU_N}{d{\bf r}_1}\right ) e^{-\beta U_N} d{\bf r}_3... d{\bf r}_N}{\int ... \int e^{-\beta U} d{\bf r}_3 ... d{\bf r}_N}$$ $$ =\frac{1}{\beta} \frac{\frac{d}{d{\bf r}_1} \left (\int ... \int e^{-\beta U_N} d{\bf r}_3...d{\bf r}_N \right )}{\int ... \int e^{-\beta U_N} d{\bf r}_3 ... d{\bf r}_N} =\frac{1}{\beta}\frac{d}{d{\bf r}_1}\ln \left ( \int ... \int e^{-\beta U_N}d{\bf r}_3 ... d{\bf r}_N\right ) \tag{S24}$$ From Equation \ref{RDF}, we have $$\int ... \int e^{-\beta U_N}d{\bf r}_3 ... d{\bf r}_N = \frac{\rho^2 Z_N}{N(N-1)} g^{(2)}({\bf r}_1, {\bf r}_2) \tag{S25}$$ Hence $$\langle F_1 \rangle = \frac{1}{\beta} \frac{d}{d{\bf r}_1}\left [ \ln \left(\frac{\rho^2 Z_N}{N(N-1)} \right ) + \ln \left (g^{(2)}({\bf r}_1, {\bf r}_2) \right) \right ]=\frac{1}{\beta} \frac{d}{{\bf r}_1}\ln g(r) \tag{S26}$$ Finally, we have $$W(r) = -\int \langle F_1 \rangle dr_1 = \int \left (\frac{1}{\beta}\frac{d}{d{\bf r}_1}\ln g(r) \right ) d{\bf r}_1 \Rightarrow \boxed{W(r)=-\frac{1}{\beta}\ln g(r)} \tag{S27}$$ (Check this handout to see how the radial distribution function $g(r)$ can be used to calculate other thermodynamic quantities such as the energy or pressure.)
3. Exercises
👨💻 Exercise 1
Given the functional form of the free energy surface in Figure 1 ($f(x_1, x_2)=x_1^4-6x_1^2+x_1+x_2^2$), estimate the timescale of transitioning from the left to right metastable states at 300 K. (Hint: One can use the transition state theory (TST) to estimate the rate constant of the process.)
Click here for the solution.
First, we need to figure out the height of the free energy barrier going from left to right metastable states. This requires determining the local minima and maxima of the free energy surface by equating the partial derivative of $f(x_1, x_2)$ with respect to $x_1$: $\frac{\partial f}{\partial x_1}=0\Rightarrow 4x_1^3-12x_1 + 1=0$ As a result, at $x_1\approx -1.7723$, $f(x_1)$ has the global minimum of $-10.7524 \text{ } \mathrm{k_{B}T}$, while a local maximum of $0.0417 \text{ } \mathrm{k_{B}T}$ occurs at $x_1\approx 0.0835$, so the barrier height is $10.7941 \text{ } \mathrm{k_{B}T}$. Given the free energy barrier height ($\Delta G^\ddagger=10.7941 \text{ } \mathrm{k_{B}T}$), now we can use transition state theory (TST) to determine the rate constant as follows: $$\boxed{k=\frac{k_B T}{h} \exp\left (\frac{-\Delta G^\ddagger}{k_B T}\right)}\tag{E1}$$ Accordingly, we have $$k=\frac{1.38 \times 10^{-23} \text{ J}/\text{K} \times 300 \text{ K}}{6.626 \times 10^{-34} \text{ J}\cdot\text{s}} \exp({-10.7524})\approx 1.34 \times 10^{8} \text{ s}^{-1}\tag{E2}$$ Therefore, the timescale of the process is $t=1/k\approx 7.5\times 10^{-9}\text{ s}=7.5 \text{ ns}$. That is, with a time step of 2 femtoseconds, it would require at least 3.7 million steps to simulate this process in a standard molecular dynamics simulation. Given currently available high-end computing resources, such a computational cost is not too demanding. However, for an even larger free energy barrier, say, $20\text{ } \mathrm{k_B T}$, the timescale quickly goes up to 77.6 microseconds. For a barrier of $30 \text{ } \mathrm{k_B T}$, which is not uncommon,
👨💻 Exercise 2
A one-dimensional simple harmonic potential with a force constant $K$ can be expressed as $U(x)=\frac{1}{2}K(x-x_0)^2$, where $x_0$ is the equilibrium position on the $x$-axis. Given this, derive the probability density distribution and Helmholtz free energy expressions for the system.
The one-dimensional harmonic potential is given by $$U(x)=\frac{1}{2}K(x-x_0)^2 \tag{E3} \label{harmonic}$$ Substituting Equation \ref{harmonic} into Equation \ref{config_boltzmann}, we have $$\nu(x) = \frac{\exp\left(-\frac{1}{2}\beta K (x-x_0)^2\right )}{\int_{-\infty}^{\infty}\exp\left(-\frac{1}{2}\beta K (x-x_0)^2\right)dx} \label{harmonic_2} \tag{E4}$$ Let $a=\sqrt{\frac{\beta K}{2}}(x-x_0) \Rightarrow da = \sqrt{\frac{\beta K}{2}}dx$, then the denominator $Z$ of Equation \ref{harmonic_2} can be calculated as below: $$Z=\int_{-\infty}^{\infty}\exp(-a^2) dx = \sqrt{\frac{2}{\beta K}}\int^{\infty}_{-\infty}\exp(-a^2)da=\sqrt{\frac{2\pi}{\beta K}}\tag{E5}$$ Therefore, the probability distribution of a one-dimensional harmonic oscillator is $$\boxed{\nu(x)=\sqrt{\frac{\beta K}{2\pi}}\exp\left (-\frac{\beta K}{2}(x-x_0)^2\right)}\tag{E6}$$ Importantly, this is a Gaussian distribution centered at $x_0$, with the standard deviation being $\sigma=1/\sqrt{\beta K}$. Then, using $F=-\frac{1}{\beta}\ln Z$, we can compute the free energy as $$\boxed{F = -\frac{1}{\beta}\ln \left ( \sqrt{\frac{2\pi}{\beta K}}\right )=-\frac{1}{2\beta}\ln (2\pi \sigma)}\tag{E7}$$Click here for the solution.
Padua, D. Encyclopedia of Parallel Computing; Springer Science & Business Media, 2011. ↩︎
Gelpi, J.; Hospital, A.; Goñi, R.; Orozco, M. Molecular Dynamics Simulations: Advances and Applications. Adv. Appl. Bioinform. Chem. 2015, 8, 37–47. ↩︎
HéninJ.; LelièvreT.; Shirts, M. R.; Valsson, O.; Delemotte, L. Enhanced Sampling Methods for Molecular Dynamics Simulations. Living J. Comput. Mol. Sci. 2022, 4 (1). ↩︎
Hsu, W.-T.; Piomponi, V.; Merz, P. T.; Bussi, G.; Shirts, M. R. Alchemical Metadynamics: Adding Alchemical Variables to Metadynamics to Enhance Sampling in Free Energy Calculations. Journal of Chemical Theory and Computation 2023. ↩︎
Ribeiro, J. M. L.; Bravo, P.; Wang, Y.; Tiwary, P. Reweighted Autoencoded Variational Bayes for Enhanced Sampling (RAVE). The Journal of Chemical Physics 2018, 149 (7), 072301. ↩︎
Tiwary, P.; Berne, B. J. Spectral Gap Optimization of Order Parameters for Sampling Complex Molecular Systems. Proceedings of the National Academy of Sciences 2016, 113 (11), 2839–2844. ↩︎
Kumar, S.; Rosenberg, J. M.; Bouzida, D.; Swendsen, R. H.; Kollman, P. A. The Weighted Histogram Analysis Method for Free-Energy Calculations on Biomolecules. I. The Method. J. Comput. Chem. 1992, 13 (8), 1011–1021. ↩︎
Kirkwood, J. G. Statistical Mechanics of Fluid Mixtures. J. Chem. Phys. 1935, 3 (5), 300–313. ↩︎
Bennett, C. H. Efficient Estimation of Free Energy Differences from Monte Carlo Data. J. Comput. Phys. 1976, 22 (2), 245–268. ↩︎
Shirts, M. R.; Chodera, J. D. Statistically Optimal Analysis of Samples from Multiple Equilibrium States. J. Chem. Phys. 2008, 129 (12), 124105. ↩︎